From Llama to LLaSA - GRPO with WER and custom repetition penalty
How I used GRPO, Whisper WER, and a custom repetition penalty to improve LLaSA-style TTS quality with audio tokens.
On this page

tl;dr - What is the Post About?
- Improving a SmolLM2-based TTS model (SmolKartoffel-135M) using GRPO training with a custom reward function
- Used Word Error Rate from Whisper transcription plus a repetition penalty as reward
- Mixed results: better voice cloning stability but some unintended effects (faster speaking with longer texts)
- Demonstrates how GRPO can be applied to audio-based LLMs beyond typical reasoning tasks
- Both models available on Hugging Face for comparison
Introduction
This will be part of a blog post series covering small experiments with Llasa-style TTS models based on SmolLM2 or Llama 3.3. The primary goal is to improve the quality of generated audio using the GRPO (Group Relative Policy Optimization) training method. The experiments will build upon the SmolKartoffel-135M model I trained earlier, focusing on using WER (Word Error Rate) from automatic transcription and a repetition penalty as a reward function.
This post does not fit chronologically in the blog series timeline, as this is a later step for the TTS training but it is the most recent topic. These are mainly just weekend projects taking at most a couple of days or evenings after work and not production ready 😄.
Baseline for the Experiments
For my baseline, I used the SmolKartoffel-135M model I trained earlier. It's based on the SmolLM2 architecture and was trained with the same custom data and scripts as the bigger Kartoffel-1B models. The training data included over 2.5M samples with about 7,000 hours of audio. I scraped this dataset from permissive German sources - mostly podcasts and OER lectures and trained the model on two RTX 3090s for 2 epochs in about 3 days.
For its size, the model actually generates pretty good audio. The voice cloning, though, is quite limited - the speaker often sounds noticeably different from the reference. Worse, the model sometimes gets stuck in repetition loops like:
Ja das it ähhhhhhhhhhhhhhhhhhhhhhhhhh
The input text was "Ja das it äh, wie soll ich es sagen? Nicht so gut." You can enforce the repetition by using a small temperature. What's happening technically is that the model falls into patterns where it repeats sequences of audio tokens, like:
<s_111><s_222><s_333><s_111><s_222><s_333><s_111><s_222><s_333>...It's not just repeating a single token but cycling through small sets of tokens. This happens with my bigger models too, and even with the original Llasa. You can usually reduce these repetitions by cranking up the temperature during generation, but in my quick tests, this often makes the voice sound less like the reference - creating an trade-off.
Setting Up the Reward Function
I wanted to start with the probably most obvious reward function you can think of, the Word Error Rate (WER) from the Whisper transcriptions of the generated audios. I used my train dataset for the texts the SmolKartoffel should generate and then I chose the same whisper model to generate the transcriptions. This reduces possible differences in transcription generation like fill words.
To not have to create weird multi-processing scripts, I gave Claude a short transcription script example that was converted to a fastAPI endpoint. Now I could just run the fastAPI on the second GPU and use the first one mainly for the training.
However I quickly noticed that the previously mentioned repetition artifacts are not penalized like I wished for. The WER is calculated with:
and the reward with:
Where:
- S: Substitutions
- D: Deletions
- I: Insertions
- H: Correct words
To convert the WER into a reward ranging from I used the exponential function . This way lower WER values result in higher rewards, while higher WER values lead to exponentially smaller rewards.
The problem is that a long repetition like "ähhhhhhhh" only counts as a single error word in the WER calculation, even though it significantly degrades audio quality. Therefore the lost reward is low ignoring that the repetition also leads to missing words.
I implemented a reward according to found repetitions. The reward is a simple regex matcher that is either true or false. A problem is that both rewards require the transcribed text, and I couldn't easily add them to the transformers rewards without transcribing everything twice. A post-processing function in the GRPOTrainer would have been useful for combining these rewards more efficiently. Therefore I only passed a single reward function to the transformers Trainer and implemented the weighting of the rewards in the reward function myself.
Here's the Python code showing how the main reward components are calculated:
...
def detect_hangups(text: str, threshold=6, min_reward=0.0, max_reward=1.0) -> float:
pattern = r'(.)\1{' + str(threshold-1) + r',}'
if re.search(pattern, text):
print(f"Found excessive repetition. Applied min_reward: {min_reward}")
return min_reward
return max_reward
...
# There is also a better way using transformations with jiwer to normalize
normalized_answer = expected_text.lower().replace(".", "").replace(",", "").replace("?", "").replace("!", "")
normalized_transcribed = transcribed.text.lower().replace(".", "").replace(",", "").replace("?", "").replace("!", "")
wer = jiwer.wer(normalized_answer, normalized_transcribed)
wer_reward = math.exp(-wer)
hangup_reward = detect_hangups(transcribed.text)
reward = None
if wer_reward is not None:
reward = (wer_reward + hangup_reward) / 2
else:
reward = hangup_rewardWe will later see, why these reward functions are probably not optimal for the optimization. The fastAPI endpoint can be found in the services/main.py file of the project repository.
Placing the vLLM Inference and Training on different GPUs
I wanted to place the vLLM inference and the training on different devices. For that I directly adjusted the grpo_trainer.py file of the transformers library. You can find the file in the dummy_patched/grpo_trainer.py of my repository. This modification is based on a specific commit of the trl library referenced at the top of the file.
However I strongly advice not to use this file and rather use the updated trl library with a native implementation of detached vLLM inference. The current version already supports placing vLLM inference on different devices in a much cleaner implementation.
I had multiple issues when using the vLLM detached inference. First of I had to disable the V1 mode of the vLLM. This is done by setting the environment variable VLLM_USE_V1=0. The second issue was that the communication for updating the weights failed. TRL has the communication GPU set to cuda:0 with PyNcclCommunicator. Therefore the inference must be placed on the cuda:0 device with CUDA_VISIBLE_DEVICES=0. So rather train on cuda:1 and serve on cuda:0. See grpo_trainer.py and vllm_client.
The Results of the GRPO-Training vs. Base-Model
The results of the GRPO Training are a bit mixed. I upload the basemodel and the GRPO variant to huggingface, as well as two spaces to test them out. So please test them yourself. Keep in mind the model is quite brittle according to unseen characters. As all data was created by transcribing it with whisper, almost no special characters like " are present. I probably should remove the characters in the spaces demo prior to passing it to the model.
Here a sample with a random speaker:
Base Model:
GRPO Model:
On the random speaker the basemodel already produces good results after training it for 2 epochs and using it with a temperature of 1. The GRPO variant performs similar or slightly worse on the random speaker. However, you can notice an undesired behaviour that the model learned with the reward function. The longer the given text is, the faster the speaker is getting. There seems to be a correlation between the text length and the speed of the speaker learned with the GRPO approach. Since the model is rewarded according to the WER this actually makes sense for long texts as the max model length is limited to ~2k tokens. The faster it speaks the more words it can generate in the limited token space. Unfortunately this also happens with texts that should result in less than 2k tokens.
For the voice cloning the GRPO training did improve the stability of the generation. The repetitions are still present however less frequent. While the base model often gets stuck in repetition loops especially with temperatures < 1.0. Additionally the GRPO model seems to also cope better with completely unseen speakers and more emotions in the reference audio. However the GRPO model also produces incomplete audios or artifacts.
Here a unseen sample with a news article and a speaker from the training data:
Die genaue Ursache des Unfalls ist derzeit noch unklar. Laut Augenzeugen soll der Kleinwagen beim Spurwechsel den Transporter touchiert haben, woraufhin beide Fahrzeuge ins Schleudern gerieten. Der Transporter kippte dabei auf die Seite und blockierte mehrere Fahrspuren. Die Feuerwehr war mit einem Großaufgebot vor Ort, um die Unfallstelle zu sichern und die Verletzten zu bergen.
Base Model:
GRPO Model:
Here a unseen sample with a children's book and a speaker from unseen data with more emotions:
Bruno bedankte sich und lief weiter. Als er das Blumenfeld erreichte, sah er tatsächlich etwas Glitzerndes zwischen den Blumen. Es war der Stern! Er war klein, warm und leuchtete schwach.
Base Model:
GRPO Model:
Summary
We could see that GRPO can also be applied to audio-based LLMs and not only to the usual thinking examples. The GRPO training produced mixed results. For random speakers, the performance was similar or slightly worse than the baseline. Interestingly, the model learned to speak faster with longer texts - an unintended consequence, likely from rewarding lower WER scores with limited token context.
The biggest improvements came in voice cloning stability. The GRPO model handles unseen speakers and emotional content a bit better, with fewer repetition loops. However, it still produces incomplete audio or artifacts.
I've uploaded both models to Hugging Face for comparison. The implementation required some workarounds, particularly in placing the vLLM inference and training on different GPUs. I recommend using the current TRL library with native support for detached vLLM inference rather than my patched version.
As always in classic RL: Be careful of possible exploits or unintended consequences when designing your reward functions. The combined WER and repetition penalty reward function didn't work that well. Maybe a reward function based on Spectral or MFCC similarity works better or if you want to finetune for a specific speaker embedding similarities or other similarities.
Additional Informations
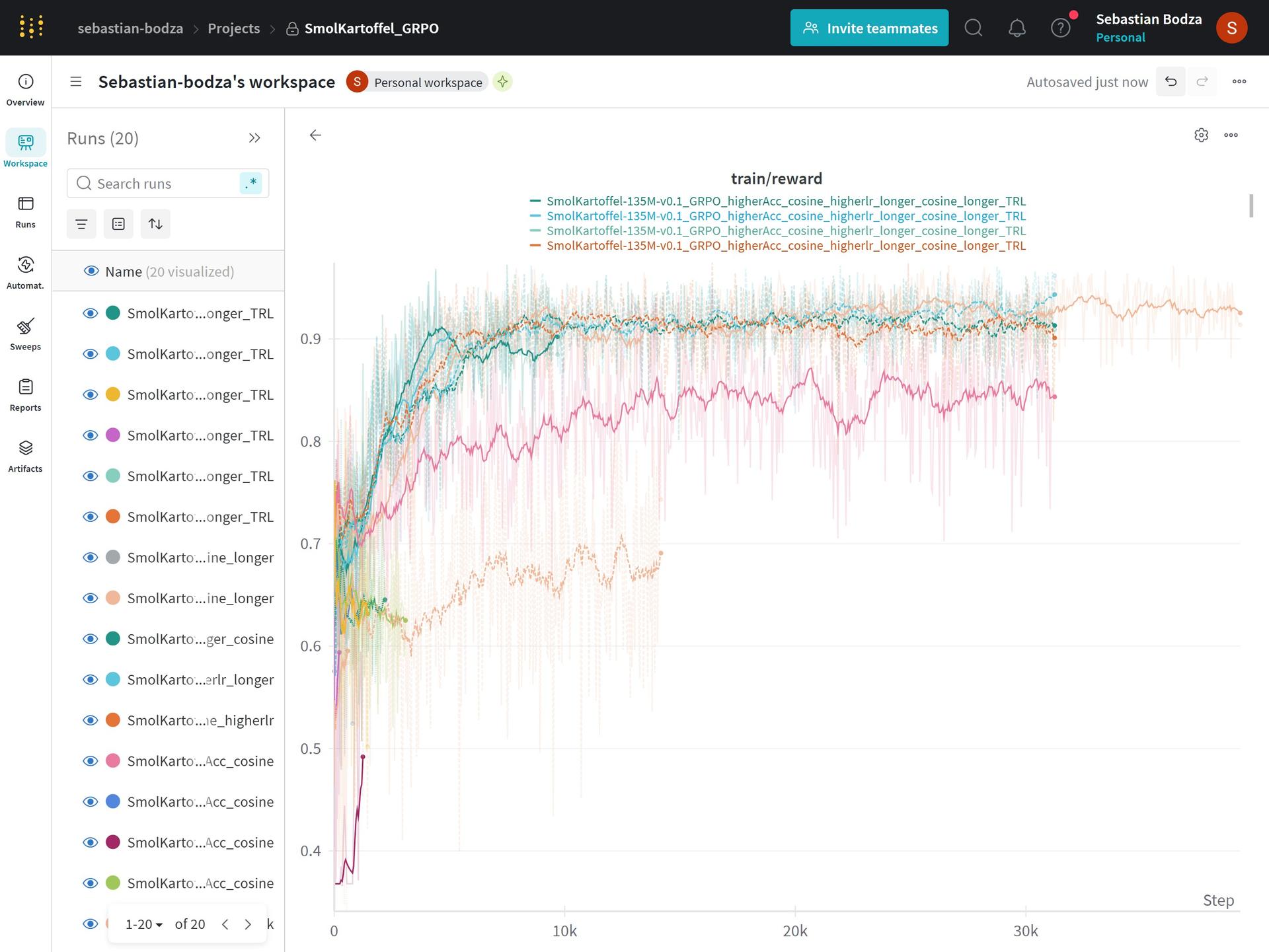
Some additional informations and images:
- The learning rate scheduler had almost no effect. The linear warmup and constant scheduler worked better than the cosine scheduler.
- The reward function had a significant impact on the model's performance.
- The training reached almost peak reward relatively quickly, in fewer than 10,000 steps.

About the author
Sebastian Bodza
AI engineer focused on LLMs, TTS, agent workflows, and practical GenAI systems built for real production constraints.
Related reading
Real-Time TTS Streaming with Orpheus and SNAC on a single RTX 3090
Build low-latency streaming TTS with Orpheus, vLLM, and SNAC on a single RTX 3090, with notes on scaling the pipeline across GPUs.
Why LLM Benchmarks Can Be Misleading - AWQ vs. GPTQ
Why official LLM benchmarks can mislead you: AWQ vs GPTQ results, custom tests, and what matters more than leaderboard scores.
Common Challenges in Adopting Open-Source LLMs
The most common open-source LLM adoption pitfalls: bad model choices, unrealistic expectations, poor prompting, and avoidable infrastructure mistakes.