Common Challenges in Adopting Open-Source LLMs
The most common open-source LLM adoption pitfalls: bad model choices, unrealistic expectations, poor prompting, and avoidable infrastructure mistakes.
On this page

tl;dr - What is the Post About?
- Hands on experience for the entry in the world of opensource LLMs
- Common mistakes you can and probably will make
- Tipps & Tricks on how to fix them
- Information mainly for the transformers library and vllm, a bit limited for ollama
False Expectations
Let me make it clear: No! A 7B model will not perform as well as GPT-4 turbo or GPT-4o! But they can be especially great if you combine them with additional information in the context or for structured generation.
On the other hand, do not underestimate that you are probably in an AI bubble. Just have a look at the Google Trends for some other LLMs.
Many people have only ever experienced the free ChatGPT versions of GPT-3.5 or now a couple of GPT-4 messages. Open-source models are catching up with closed models, and there are real viable options for GPT-3.5 alternatives. Llama-3.1 has caught up to GPT-4.
Be warned languages other than english can be challenging! Your best bet for German are:
- Mistral Large 2 (non commercial only!)
- Mistral Nemo
- Mixtral (8x7B and 8x22B)
- LLama-3.1
- CommandR+ (very good and underrated, non commercial only!)
or less know local finetunes. Some popular ones are:
- German: Different Models from Disco Research like or the LeoLM models
- Multilingual: For Multilingual models you can have a look at the Occiglot Euro LLM Leaderboard
Choosing the Wrong Model and Trusting Benchmarks
Just like in the automotive industry, where everybody optimizes for driving cycles, people optimize LLMs for benchmarks. So, be prepared for discrepancies between benchmarks and real-world performance. Just have a look at the updated Hugging Face leaderboard. The models that dropped the most are small, crazy model merges that dropped from place 4 to 60 or 5 to 48, just by changing the benchmarks the models are evaluated on!
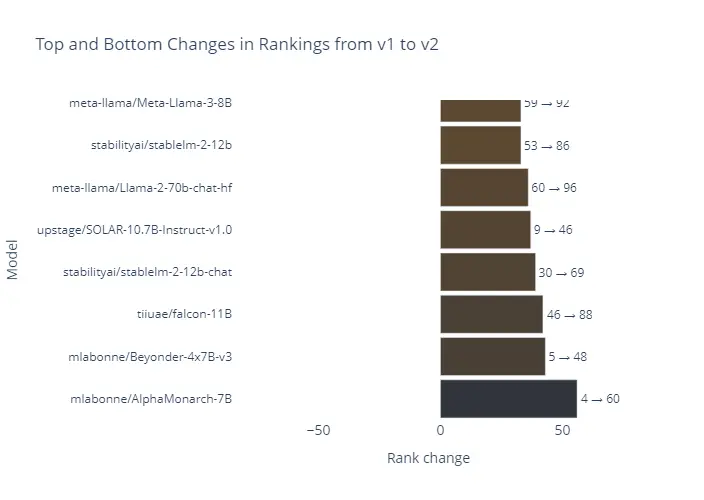
To make it clear, all models are optimized to a certain point. However, if done properly, the direct questions/tests are not used during the training.
Another thing to keep in mind is that various benchmarks test different capabilities of the models. Choose a benchmark that fits closest to your use case or that resembles the most important property.
| Benchmark | Description | Elements Benchmarked | |-----------|-------------|----------------------| | MMLU-Pro | A multichoice knowledge dataset with ten choices per question | Knowledge, Reasoning | | GPQA | A knowledge dataset with questions designed by domain experts to be challenging for laypersons but manageable for experts | Specialized Knowledge | | MuSR | A dataset of algorithmically generated complex problems (murder mysteries, object placement, team allocation) of around 1K words in length | Long-range Context Parsing, Reasoning | | MATH | A compilation of high-school-level competition math problems | Mathematical Problem-Solving, Format Adherence | | IFEval | A dataset testing the capability of models to follow explicit instructions | Instruction Following, Format Adherence | | BBH | A subset of 23 challenging tasks from the BigBench dataset | Multistep Arithmetic, Algorithmic Reasoning, Language Understanding, World Knowledge |
My favorite test here is the IFEval. This test includes a lot of constraints, such as including a keyword, frequency of keywords, JSON formatting, length constraints, different languages, formatting in a specified number of bullet points, punctuation constraints, all uppercase/lowercase, starts with/ends with, and many more.
When building automations, I do not care about the knowledge. The model just has to process some information in the context and adhere to a desired output format. If I want a general Q&A chatbot, the knowledge might become more important.
Underestimating Resource Requirements
Many users underestimate the hardware requirements for large language models. As the name implies, these models are really large and have grown over time. Older BERT models were in the range of 400 million parameters. The smallest Llama 3.1 model starts at 8 billion parameters.
The models are almost all trained in reduced precision of BF16 (FP16), so a coarse rule of thumb for the required VRAM amount is 2-3 times the parameter count. Alternatively, you can look at the size of the weights, which is the minimum needed to load the model, plus some overhead and space for the actual context. For instance, 50 GB+ model weights won't fit into 24 GB of VRAM.
Your best bet here is to use a VRAM estimator: https://huggingface.co/spaces/hf-accelerate/model-memory-usage
Just paste the model name from huggingface and adjust the precision to float16/bfloat16. Keep in mind you need some overhead for the context etc.
| dtype | Largest Layer or Residual Group | Total Size | Training using Adam (Peak vRAM) | |-----------|-------------|----------------------|-----------| | float16/bfloat16 | 1002.0 MB | 14.1 GB | 56.42 GB |
So the model will most likely not run with a good speed on your 10 year old system 😊
Overestimating Resource Requirements
Many users assume they need top-tier hardware to run any LLM, but recent advancements in model optimization have made these models more accessible.
Model quantization significantly reduces the VRAM requirements and leads to faster token/s with optimized kernels. These methods compress models while maintaining most of their performance, allowing them to run on consumer-grade hardware. For an 8B or even a 70B model, you do not need server-grade hardware. Let's take the same tool as before:
| dtype | Largest Layer or Residual Group | Total Size | Training using Adam (Peak vRAM) | |-----------|-------------|----------------------|-----------| | float16/bfloat16 | 1.96 GB | 129.77 GB | 519.09 GB | | int8 | 1002.0 MB | 64.89 GB | N/A | | int4 | 501.0 MB | 32.44 GB | N/A |
As you can see, with int4 quantization, we can run the model on two RTX 3090s or RTX 4090s, each with 24 GB of VRAM. However, quantization does not come without its disadvantages. While the losses are marginal for int8 quantization, int4 quantization has a impact on model performance. Nevertheless, if you compare a smaller fp16 model with a larger int4 model, the larger int4 model will most likely always outperform the smaller, higher-precision model.
Setting up the prompt template
This is one of the hardest things to get right, when there is just no Information on the model card in huggingface.
However things got alot easier with the help of apply_chat_template from the transformers library. Thanks hf 🤗!
Every model has it's own template that you have to use to get proper results. Not using the right template can can result in varying results. Basically you could not even notice it in the beginning and just get a slight performance degradation or on the other side the model could respond with complete gibberish or unformatted code. Hurting the performance alot!
So to shorten things up: Always try to use the apply_chat_template from the unquantised/original model! There was more then once where the chat-Template was not properly uploaded to the quantized model.
This function takes the template from the models tokenizer_config.json from the huggingface model.
But even this is no guarantee that the proper template is used!
Just have a look at the Mixtral 8x7B Instruct commit. The model was released on 11.12.2023 and the commit was just merged a month ago (July 2024). There were multiple issues, one of them a simple missing space between the start token and the INST token: <s>▁[INST]
Here an example for meta-llama/Meta-Llama-3.1-8B-Instruct:
...
"bos_token": "<|begin_of_text|>",
"chat_template": "{{- bos_token }}\n{%- if custom_tools is defined %}\n {%- set tools = custom_tools %}\n{%- endif %}\n{%- if not tools_in_user_message is defined %}\n {%- set tools_in_user_message = true %}\n{%- endif %}\n{%- if not date_string is defined %}\n {%- set date_string = \"26 Jul 2024\" %}\n{%- endif %}\n{%- if not tools is defined %}\n {%- set tools = none %}\n{%- endif %}\n\n{#- This block extracts the system message, so we can slot it into the right place. #}\n{%- if messages[0]['role'] == 'system' %}\n {%- set system_message = messages[0]['content']|trim %}\n {%- set messages = messages[1:] %}\n{%- else %}\n {%- set system_message = \"\" %}\n{%- endif %}\n\n{#- System message + builtin tools #}\n{{- \"<|start_header_id|>system<|end_header_id|>\\n\\n\" }}\n{%- if builtin_tools is defined or tools is not none %}\n {{- \"Environment: ipython\\n\" }}\n{%- endif %}\n{%- if builtin_tools is defined %}\n {{- \"Tools: \" + builtin_tools | reject('equalto', 'code_interpreter') | join(\", \") + \"\\n\\n\"}}\n{%- endif %}\n{{- \"Cutting Knowledge Date: December 2023\\n\" }}\n{{- \"Today Date: \" + date_string + \"\\n\\n\" }}\n{%- if tools is not none and not tools_in_user_message %}\n {{- \"You have access to the following functions. To call a function, please respond with JSON for a function call.\" }}\n {{- 'Respond in the format {\"name\": function name, \"parameters\": dictionary of argument name and its value}.' }}\n {{- \"Do not use variables.\\n\\n\" }}\n {%- for t in tools %}\n {{- t | tojson(indent=4) }}\n {{- \"\\n\\n\" }}\n {%- endfor %}\n{%- endif %}\n{{- system_message }}\n{{- \"<|eot_id|>\" }}\n\n{#- Custom tools are passed in a user message with some extra guidance #}\n{%- if tools_in_user_message and not tools is none %}\n {#- Extract the first user message so we can plug it in here #}\n {%- if messages | length != 0 %}\n {%- set first_user_message = messages[0]['content']|trim %}\n {%- set messages = messages[1:] %}\n {%- else %}\n {{- raise_exception(\"Cannot put tools in the first user message when there's no first user message!\") }}\n{%- endif %}\n {{- '<|start_header_id|>user<|end_header_id|>\\n\\n' -}}\n {{- \"Given the following functions, please respond with a JSON for a function call \" }}\n {{- \"with its proper arguments that best answers the given prompt.\\n\\n\" }}\n {{- 'Respond in the format {\"name\": function name, \"parameters\": dictionary of argument name and its value}.' }}\n {{- \"Do not use variables.\\n\\n\" }}\n {%- for t in tools %}\n {{- t | tojson(indent=4) }}\n {{- \"\\n\\n\" }}\n {%- endfor %}\n {{- first_user_message + \"<|eot_id|>\"}}\n{%- endif %}\n\n{%- for message in messages %}\n {%- if not (message.role == 'ipython' or message.role == 'tool' or 'tool_calls' in message) %}\n {{- '<|start_header_id|>' + message['role'] + '<|end_header_id|>\\n\\n'+ message['content'] | trim + '<|eot_id|>' }}\n {%- elif 'tool_calls' in message %}\n {%- if not message.tool_calls|length == 1 %}\n {{- raise_exception(\"This model only supports single tool-calls at once!\") }}\n {%- endif %}\n {%- set tool_call = message.tool_calls[0].function %}\n {%- if builtin_tools is defined and tool_call.name in builtin_tools %}\n {{- '<|start_header_id|>assistant<|end_header_id|>\\n\\n' -}}\n {{- \"<|python_tag|>\" + tool_call.name + \".call(\" }}\n {%- for arg_name, arg_val in tool_call.arguments | items %}\n {{- arg_name + '=\"' + arg_val + '\"' }}\n {%- if not loop.last %}\n {{- \", \" }}\n {%- endif %}\n {%- endfor %}\n {{- \")\" }}\n {%- else %}\n {{- '<|start_header_id|>assistant<|end_header_id|>\\n\\n' -}}\n {{- '{\"name\": \"' + tool_call.name + '\", ' }}\n {{- '\"parameters\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- \"}\" }}\n {%- endif %}\n {%- if builtin_tools is defined %}\n {#- This means we're in ipython mode #}\n {{- \"<|eom_id|>\" }}\n {%- else %}\n {{- \"<|eot_id|>\" }}\n {%- endif %}\n {%- elif message.role == \"tool\" or message.role == \"ipython\" %}\n {{- \"<|start_header_id|>ipython<|end_header_id|>\\n\\n\" }}\n {%- if message.content is mapping or message.content is iterable %}\n {{- message.content | tojson }}\n {%- else %}\n {{- message.content }}\n {%- endif %}\n {{- \"<|eot_id|>\" }}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|start_header_id|>assistant<|end_header_id|>\\n\\n' }}\n{%- endif %}\n",
"clean_up_tokenization_spaces": true,
"eos_token": "<|eot_id|>",
...
}The chat_template however can be kind of hard to read. To get an example of a properly formatted chat we can use the following Code:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3.1-70B-Instruct")
chat = [
{"role": "user", "content": "<Some long text i want to get summarized. Include that the summary should be in bullet points with leading Summary:>"},
{"role": "assistant", "content": "Summary:\n-"},
]
chat_template = tokenizer.apply_chat_template(chat, tokenize=False)
print(chat_template)The problem has already been fixed super fast in collab with Hugging Face. Thanks! 🤗
This outputs the proper template. The highlighting of the assistant parts will get relevant in the following part:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
Cutting Knowledge Date: December 2023
Today Date: 26 Jul 2024
<|eot_id|><|start_header_id|>user<|end_header_id|>
<Some long text i want to get summarized. Include that the summary should be in bullet points with leading Summary:><|eot_id|><|start_header_id|>assistant<|end_header_id|>
Summary:
-<|eot_id|>Let's compare this to the AWQ version from hf quant:
...
"bos_token": "<|begin_of_text|>",
"chat_template": "{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}",
"clean_up_tokenization_spaces": true,
"eos_token": "<|eot_id|>",Seems like alot is missing, the complete default system prompt! Not only that, it also behaves differently, when the last message is an assistant message. The hf-quant version adds the assistant role twice.
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
<Some long text i want to get summarized. Include that the summary should be in bullet points with leading Summary:><|eot_id|><|start_header_id|>assistant<|end_header_id|>
Summary:
-<|eot_id|><|start_header_id|>assistant<|end_header_id|>I like to prefill the assistant to stick better to my desired template. Therefore I apply regularly the chat-template with the assistant message and remove the eos token chat_template = chat_template.removesuffix(tokenizer.eos_token)
Not Tapping into the Full Potential of OS LLMs
Besides prefilling like in the example above, which I think only Claude supports to a certain amount, you can also use constrained decoding. OpenAI and other providers just allow the usage of a JSON mode to return a JSON object as well as function calling. Especially the function calling with the "required" parameters and the enum can be used for a categorization. But what if you want a specific output format? There constrained decoding comes in handy.
AFAIK it is not possible to constrain the decoding with the OpenAI models, like for the transformer models. This intantionally for security reasons. You need access to low level logits and this can be used to get informations about the model size and parameters. The paper Stealing Part of a Production Language Model and the library LMQL provide a better explanation than I could.
What can this be used for? Constrained decoding can improve the amount of parsable JSON output and ensure a specific output style besides just JSON. Let's take the example from the SGLang Github:
@sgl.function
def regular_expression_gen(s):
s += "Q: What is the IP address of the Google DNS servers?\n"
s += "A: " + sgl.gen(
"answer",
temperature=0,
regex=r"((25[0-5]|2[0-4]\d|[01]?\d\d?).){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)",
)Here we can define that the answer should always be a proper IP-Adress trough the regex pattern. The possibilities are much broader and you can constrain the decoding to a specific regex pattern to your needs.
Another example is json generation with predefined word lengths, categories etc. :
character_regex = (
r"""\{\n"""
+ r""" "name": "[\w\d\s]{1,16}",\n"""
+ r""" "house": "(Gryffindor|Slytherin|Ravenclaw|Hufflepuff)",\n"""
+ r""" "blood status": "(Pure-blood|Half-blood|Muggle-born)",\n"""
+ r""" "occupation": "(student|teacher|auror|ministry of magic|death eater|order of the phoenix)",\n"""
+ r""" "wand": \{\n"""
+ r""" "wood": "[\w\d\s]{1,16}",\n"""
+ r""" "core": "[\w\d\s]{1,16}",\n"""
+ r""" "length": [0-9]{1,2}\.[0-9]{0,2}\n"""
+ r""" \},\n"""
+ r""" "alive": "(Alive|Deceased)",\n"""
+ r""" "patronus": "[\w\d\s]{1,16}",\n"""
+ r""" "bogart": "[\w\d\s]{1,16}"\n"""
+ r"""\}"""
)
@sgl.function
def character_gen(s, name):
s += name + " is a character in Harry Potter. Please fill in the following information about this character.\n"
s += sgl.gen("json_output", max_tokens=256, regex=character_regex)Just have a look at their Github project, it is a great library! The only drawback is that as of my latest tests a couple months ago only linux was supported. I did not look to much into it and just used the linux machine 😊.
Some more projects that might be interesting are:
Not Updating the Inference Library for new models
A new model was released and you are eager to try it out. Be warned, more then once there were issues with inference libraries not properly supporting the new models. Starting with e.g. the Granite models. The bias term was altered and all of the inference libraries like vllm or llama.cpp were broken at release. The problem here is that the model still outputted at least some coherent text. Keep that in mind, try first the official implementation and compare that to your desired inference library.
Before diving headfirst into using the new model with your preferred inference library, take a step back and verify its compatibility. For vllm the supported models are usually in the releases like:
# What's Changed
* [Docs] Announce llama3.1 support by @WoosukKwon in #6688## Model Support
### LLM
* Added support for Falcon (#5069)
* Added support for IBM Granite Code models (#4636)Not optimizing the prompts
Let's make it clear OpenAI is just great, because the models are easier to handle. They stick very well to the given prompt. Most OpenSource models on the other hand have sometimes a hard time sticking to your constraints.
A real world example is the translation of a dataset with natural language from english to german while always using the informal 'Du'. Mixtral answered in 1/5 to 1/4 times in german to the given instrucion. And that is the optimized form with 'In-Context learning' aka providing multiple examples. Without this the quota was even worse.
Always start off in small batches and scale them up. For example optimize with 10 prompts if you are satisfied, scale to 100 examples and finally to the full dataset. Also always keep some cleaning techniques in mind and try to use prefill! It really helps alot!
That's it as of now. I will be making more hands-on posts in the future!

About the author
Sebastian Bodza
AI engineer focused on LLMs, TTS, agent workflows, and practical GenAI systems built for real production constraints.
Related reading
Faster LLMs with Quantization - How to get faster inference times with quantization
A practical look at LLM quantization tradeoffs, benchmark results, and what actually improves vLLM inference speed in production.
Why LLM Benchmarks Can Be Misleading - AWQ vs. GPTQ
Why official LLM benchmarks can mislead you: AWQ vs GPTQ results, custom tests, and what matters more than leaderboard scores.
From Llama to LLaSA - GRPO with WER and custom repetition penalty
How I used GRPO, Whisper WER, and a custom repetition penalty to improve LLaSA-style TTS quality with audio tokens.